About STAC The STAC Specification
The STAC Specification lives as easily readable markdown pages on github, as the community aspires to keep STAC very approachable. So while this page gives a slightly deeper overview, don't hesitate to dive directly into the spec.
One thing to emphasize is that the specification is designed to be flexible and extensible. So if it seems a bit 'light', that is by design, so that different domains and tools can easily make it their own. The extensions section of the spec, detailed below, is where the community collaborates on more detail about specific data types and new functionality.
Key to the STAC approach is JSON's extensibility. While the spec does provide JSON Schemas for validation (easily usable with online tools like STACLint.com), JSON validation won’t complain if you have extra fields, adding more fields allows you to support a variety of data types and implementations. Flexibility and extensibility are core tenets of STAC.
Item
Fundamental to any STAC, a STAC Item represents an atomic collection of inseparable data and metadata. A STAC Item is a GeoJSON feature and can be easily read by any modern GIS or geospatial library. The STAC Item JSON specification includes additional fields for:
- the time the asset represents
- a thumbnail for quick browsing
- asset links, links to the described data
- relationship links, allowing users to traverse other related STAC Items
A STAC Item can contain additional fields and JSON structures to enable data providers to expose rich metadata and software developers to create intuitive tools.
{
"stac_version": "1.0.0",
"type": "Feature",
"id": "20201211_223832_CS2",
"bbox": [],
"geometry": {},
"properties": {},
"collection": "simple-collection",
"links": [],
"assets": {}
}Catalog
The STAC Catalog provides a flexible structure to link various STAC Items together to be crawled or browsed. The spec is quite simple, just a JSON that:
- contains a list of STAC Items
- contains a list of child STAC Catalogs - allowing a hierarchical grouping of STAC Items
There are no restrictions on the way catalogs are organized. Most implementations use a set of 'sub-catalogs' (a catalog that is linked to from another catalog) to group the items in some sensible way. It can be easily extended, for example to include additional metadata to further describe its holdings, as the STAC Collection does.
{
"stac_version": "1.0.0",
"type": "Catalog",
"id": "20201211_223832_CS2",
"description": "A simple catalog example",
"links": []
}Collection
A STAC Collection provides additional information about a spatio-temporal collection of data. It extends Catalog directly, layering on additional fields to enable description of things like the spatial and temporal extent of the data, the license, keywords, providers, etc. It in turn can easily be extended for additional collection level metadata. It is used standalone by parts of the STAC community, as a lightweight way to describe data holdings.
{
"stac_version": "1.0.0",
"type": "Collection",
"license": "ISC",
"id": "20201211_223832_CS2",
"description": "A simple collection example",
"links": [],
"extent": {},
"summaries": {}
}STAC API
STAC API The STAC API specification is a bit different from the others. Instead of just specifying JSON and links that could be implemented with no moving parts, it defines a RESTful service interface for search. It dynamically generates a GeoJSON FeatureCollection of STAC Items in response to a user query.
The core of the spec is a single endpoint:
/stac/searchIt takes a JSON object that can filter on date and time:
{
"bbox": [5.5, 46, 8, 47.4],
"time": "2018-02-12T00:00:00Z/2018-03-18T12:31:12Z"
}This tells the server to return all the catalog items it has that are from the second half of March, 2018 and that intersect with this area:
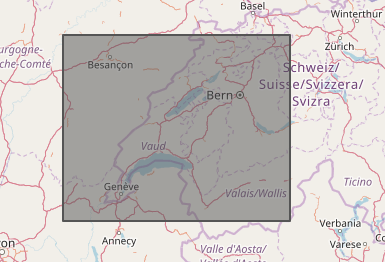
The return format is a GeoJSON FeatureCollection with features compliant with the Item spec for STAC. It returns to a limit optionally requested by the client, and includes pageable links to iterate through any results past that limit.
STAC API has worked to align with the OGC's WFS 3 specification, and ideally it evolves so as much of the STAC API functionality as possible is in WFS. For more about this see the FAQ.
Extensions
While the core specification says nothing about particular types of data, the extensions folder is where one can find domain-specific fields that can be easily added to any STAC Item. It is a place where any implementor can propose fields that are potentially more widely applicable than just their data. Each extension is labeled with a ‘maturity classification’ that lets others know how likely the extension is to change in the future.
The goal is to enable specific communities to work together to find a ‘good enough’ set of common metadata.
Dynamic and Static Catalogs
The final bit to draw attention to is the two different types of catalogs - static and dynamic.
A static catalog is one that is implemented as a set of flat files on a web server or an object store like S3 or Google Cloud Storage. A dynamic catalog is one that generates its responses dynamically, generally backed by some sort of server. The core Item, Catalog and Collection specs can be fully implemented by either, and the spec is designed to be agnostic to how it is implemented. This decision was made to make the lowest possible barrier to exposing data as STAC. For many the simplest thing to do is to simply create files and put them online. But large data providers like Planet and DigitalGlobe have already invested significant effort and resources in generating dynamic API’s and indexes for their customers to query their imagery holdings. For them it is actually easier to implement a dynamic STAC instead of trying to re-architect their core platforms. But static catalogs have an additional use cases for large providers, enabling a fail safe point of truth. A static catalog can be generated from the dynamic index, stored on the cloud, and then easily used for disaster recovery due to the incredible reliability of AWS S3 and Google Cloud Storage.
Client libraries like STAC Browser are able to treat dynamic and static catalogs the same, as they both expose the exact same information. The one thing dynamic catalogs can do that static ones can't is offer the /search/ endpoint. Though as the ecosystem of dynamic STAC servers improves it will be quite easy to use an off the shelf server to ingest the static catalog and provide a dynamic version of it to enable search.