Reading Data from the STAC API¶
The Planetary Computer catalogs the datasets we host using the STAC (SpatioTemporal Asset Catalog) specification. We provide a STAC API endpoint that can be used to search our datasets by space, time, and more. This quickstart will show you how to search for data using our STAC API and open-source Python libraries. For more on how to use our STAC API from R, see Reading data from the STAC API with R.
To get started you'll need the pystac-client library installed. You can install it via pip:
> pip install pystac-clientFirst we'll use pystac-client to open up our STAC API:
from pystac_client import Client
catalog = Client.open("https://planetarycomputer.microsoft.com/api/stac/v1")
Searching¶
We can use the STAC API to search for assets meeting some criteria. This might include the date and time the asset covers, is spatial extent, or any other property captured in the STAC item's metadata.
In this example we'll search for imagery from Landsat Collection 2 Level-2 area around Microsoft's main campus in December of 2020.
time_range = "2020-12-01/2020-12-31"
bbox = [-122.2751, 47.5469, -121.9613, 47.7458]
search = catalog.search(collections=["landsat-8-c2-l2"], bbox=bbox, datetime=time_range)
items = search.get_all_items()
len(items)
In that example our spatial query used a bounding box with a bbox. Alternatively, you can pass a GeoJSON object as intersects
area_of_interest = {
"type": "Polygon",
"coordinates": [
[
[-122.2751, 47.5469],
[-121.9613, 47.9613],
[-121.9613, 47.9613],
[-122.2751, 47.9613],
[-122.2751, 47.5469],
]
],
}
time_range = "2020-12-01/2020-12-31"
search = catalog.search(
collections=["landsat-8-c2-l2"], intersects=area_of_interest, datetime=time_range
)
items is a pystac.ItemCollection. We can see that 4 items matched our search criteria.
len(items)
Each pystac.Item in this ItemCollection includes all the metadata for that scene. STAC Items are GeoJSON features, and so can be loaded by libraries like geopandas.
import geopandas
df = geopandas.GeoDataFrame.from_features(items.to_dict(), crs="epsg:4326")
df
We can use the eo extension to sort the items by cloudiness. We'll grab an item with low cloudiness:
selected_item = min(items, key=lambda item: item.properties["eo:cloud_cover"])
selected_item
Each STAC item has one or more Assets, which include links to the actual files.
import rich.table
table = rich.table.Table("Asset Key", "Descripiption")
for asset_key, asset in selected_item.assets.items():
# print(f"{asset_key:<25} - {asset.title}")
table.add_row(asset_key, asset.title)
table
Here, we'll inspect the rendered_preview asset.
selected_item.assets["rendered_preview"].to_dict()
from IPython.display import Image
Image(url=selected_item.assets["rendered_preview"].href, width=500)
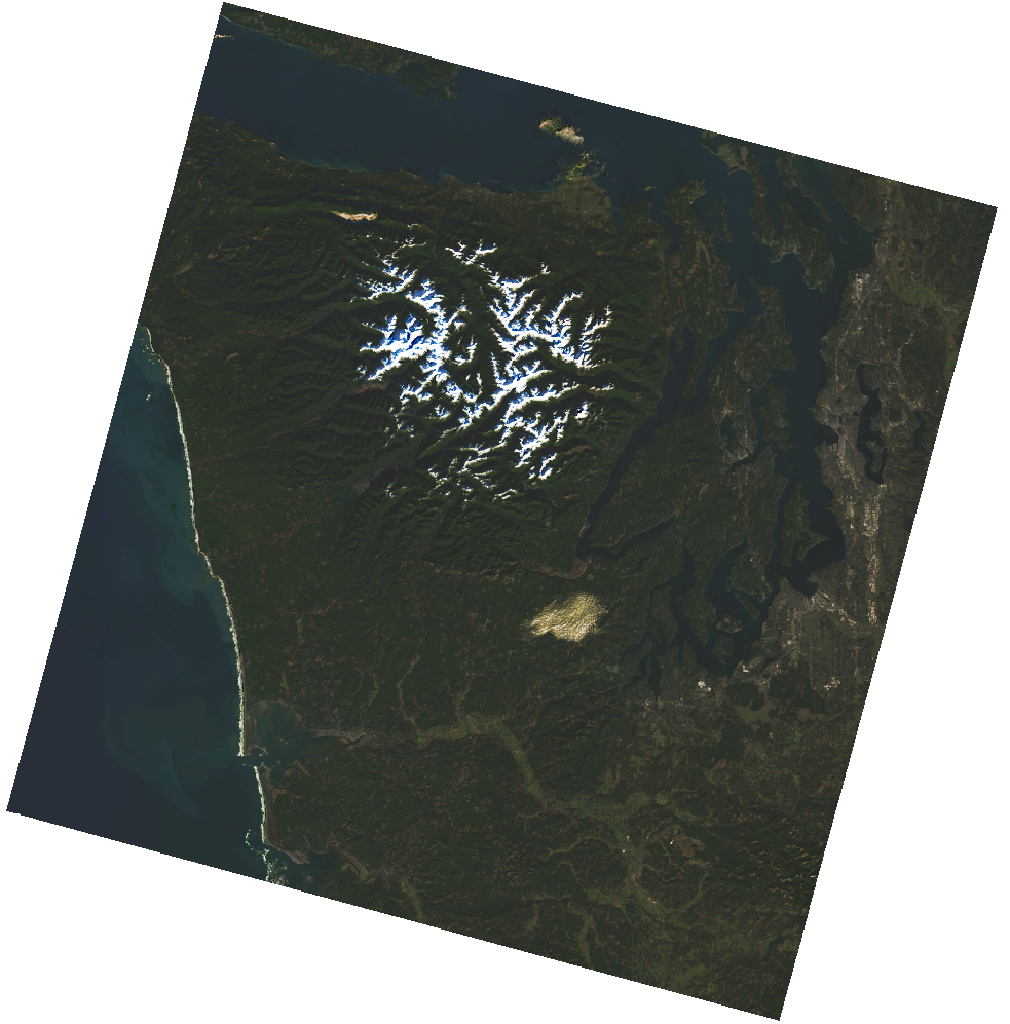
That rendered_preview asset is generated dynamically from the raw data using the Planetary Computer's data API. We can access the raw data, stored as Cloud Optimzied GeoTIFFs in Azure Blob Storage, using one of the other assets. That said, we do need to do one more thing before accessing the data. If we simply made a request to the file in blob storage we'd get a 404:
import requests
url = selected_item.assets["SR_B2"].href
print("Accessing", url)
response = requests.get(url)
response
That's because the Plantary Computer uses Azure Blob Storage SAS Tokens to enable access to our data, which allows us to provide the data for free to anyone, anywhere while maintaining some control over the amount of egress for datasets.
To get a token for access, you can use the Planetary Computer's Data Authentication API. You can access that anonymously, or you can provide an API Key for higher rate limits and longer-lived tokens.
You can also use the planetary-computer package to generate tokens and sign asset HREFs for access. You can install via pip with
> pip install planetary-computerimport planetary_computer
# PC_SDK_SUBSCRIPTION_KEY
signed_href = planetary_computer.sign(selected_item).assets["SR_B2"].href
# import xarray as xr
import rioxarray
ds = rioxarray.open_rasterio(signed_href, overview_level=4).squeeze()
img = ds.plot(cmap="Blues", add_colorbar=False)
img.axes.set_axis_off();

import stackstac
ds = stackstac.stack(planetary_computer.sign(items))
ds
Searching on additional properties¶
Previously, we searched for items by space and time. Because the Planetary Computer's STAC API supports the query parameter, you can search on additional properties on the STAC item.
For example, collections like sentinel-2-l2a and landsat-8-c2-l2 both implement the eo STAC extension and include an eo:cloud_cover property. Use query={"eo:cloud_cover": {"lt": 20}} to return only items that are less than 20% cloudy.
time_range = "2020-12-01/2020-12-31"
bbox = [-122.2751, 47.5469, -121.9613, 47.7458]
search = catalog.search(
collections=["sentinel-2-l2a"],
bbox=bbox,
datetime=time_range,
query={"eo:cloud_cover": {"lt": 20}},
)
items = search.get_all_items()
Other common uses of the query parameter is to filter a collection down to items of a specific type, For example, the GOES-CMI collection includes images from various when the satellite is in various modes, which produces images of either the Full Disk of the earth, the continental United States, or a mesoscale. You can use goes:image-type to filter down to just the ones you want.
search = catalog.search(
collections=["goes-cmi"],
bbox=[-67.2729, 25.6000, -61.7999, 27.5423],
datetime=["2018-09-11T13:00:00Z", "2018-09-11T15:40:00Z"],
query={"goes:image-type": {"eq": "MESOSCALE"}},
)
Analyzing STAC Metadata¶
STAC items are proper GeoJSON Features, and so can be treated as a kind of data on their own.
search = catalog.search(
collections=["sentinel-2-l2a"],
bbox=[-124.2751, 45.5469, -110.9613, 47.7458],
datetime="2020-12-26/2020-12-31",
)
items = search.get_all_items()
df = geopandas.GeoDataFrame.from_features(items.to_dict(), crs="epsg:4326")
df[["geometry", "datetime", "s2:mgrs_tile", "eo:cloud_cover"]].explore(
column="eo:cloud_cover", style_kwds={"fillOpacity": 0.1}
)
Or we can plot cloudiness of a region over time.
import pandas as pd
search = catalog.search(
collections=["sentinel-2-l2a"],
bbox=[-124.2751, 45.5469, -123.9613, 45.7458],
datetime="2020-01-01/2020-12-31",
)
items = search.get_all_items()
df = geopandas.GeoDataFrame.from_features(items.to_dict())
df["datetime"] = pd.to_datetime(df["datetime"])
ts = df.set_index("datetime").sort_index()["eo:cloud_cover"].rolling(7).mean()
ts.plot(title="eo:cloud-cover (7-scene rolling average)");

Working with STAC Catalogs and Collections¶
Our catalog is a STAC Catalog that we can crawl or search. The Catalog contains STAC Collections for each dataset we have indexed (which is not the yet the entirity of data hosted by the Planetary Computer).
Collections have information about the STAC Items they contain. For instance, here we look at the Bands available for Landsat 8 Collection 2 Level 2 data:
import pandas as pd
landsat = catalog.get_collection("landsat-8-c2-l2")
pd.DataFrame(landsat.extra_fields["summaries"]["eo:bands"])
We can see what Assets are available on our item with:
pd.DataFrame.from_dict(landsat.extra_fields["item_assets"], orient="index")[
["title", "description", "gsd"]
]
Some collections, like Daymet include collection-level assets. You can use the .assets property to access those assets.
collection = catalog.get_collection("daymet-daily-na")
collection
Just like assets on items, these assets include links to data in Azure Blob Storage.
asset = collection.assets["zarr-https"]
asset
import fsspec
import xarray as xr
store = fsspec.get_mapper(asset.href)
ds = xr.open_zarr(store, **asset.extra_fields["xarray:open_kwargs"])
ds